
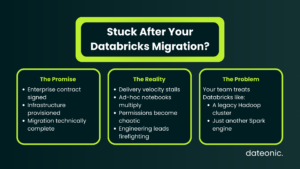
The ink is dry on your enterprise contract, the infrastructure is fully provisioned, and the migration is technically complete. Yet, the anticipated surge in delivery velocity hasn’t materialized. Instead of shipping robust data products, your engineering leads are bogged down in operational friction.
We call this the „Post-Migration Plateau.” It happens when teams default to treating Databricks like their legacy on-prem Hadoop clusters or merely as an on-demand Spark compute engine. Ad-hoc notebooks multiply, permissions become a tangled web, and the platform’s advanced ecosystem capabilities remain dormant.
The bottleneck to scaling your data platform isn’t the technology – it’s the gap between theoretical knowledge and practical, architectural execution.
Why Generic Certifications Won’t Fix Your Delivery Pipeline
Faced with this plateau, data leaders generally take one of two paths: they spend six to nine months hunting for a mythical „Databricks Unicorn,” or they purchase generic, self-paced certification tracks for their current staff.
Neither approach solves the underlying architectural rot.
The „Hello World” Trap
Standard certifications are designed to teach syntax, not enterprise architecture. They will successfully teach an engineer how to write a PySpark dataframe or initialize a cluster. However, they will not teach your team how to safely deploy that code across strict Dev, Staging, and Prod environments using proper software engineering lifecycle practices.
Ignoring the Ecosystem Gap
Because standard training ignores the broader capabilities of the platform, teams end up building disjointed solutions. If your engineers don’t understand how to implement automated CI/CD pipelines or structurally isolate workloads, your cutting-edge platform quickly devolves into an expensive, unmanageable swamp.
The Dateonic Way: Opinionated Architecture and Hands-On Enablement
The difference between a failing deployment and a resilient data platform comes down to opinionated architecture. A high-impact Databricks Bootcamp shouldn’t just teach Spark syntax; it must instill the „Right Way” to govern, deploy, and scale.
| The Legacy Approach | The Dateonic Way |
|---|---|
| Compute: Treating Databricks as a basic Spark cluster for ad-hoc queries. | Ecosystem: Utilizing Delta Live Tables and serverless compute for automated pipelines. |
| Deployment: Manually cloning notebooks between workspaces. | Engineering Rigor: Fully automated CI/CD using Databricks Asset Bundles (DABs). |
| Security: Messy, workspace-level ACLs applied as an afterthought. | Governance: Unity Catalog implemented from Day 1 with strict row/table-level privileges. |
Unity Catalog as a First-Class Citizen
Data governance cannot be a bolted-on afterthought. Our methodology requires treating data governance as a foundational pillar. We teach teams how to architect Unity Catalog correctly, designing robust row and table-level privileges and logically isolating team workspaces from the ground up.
Enforcing Engineering Rigor
We shift data teams away from the brittle practice of manually running cells in a notebook. By integrating Databricks Asset Bundles (DABs), we train your engineers to apply strict software engineering best practices to data pipelines, ensuring every deployment is version-controlled, tested, and automated.
Inside the Dateonic Databricks Bootcamp
Our intensive workshop is designed for CTOs, Data Platform Leads, and Architects who need to turn a struggling or junior team into platform experts. We focus exclusively on your company’s actual codebase and infrastructure.
- Phase 1: Architectural Foundations & Governance: We establish the bedrock of your platform. This includes comprehensive Unity Catalog setup, identity management strategies, and secure workspace isolation.
- Phase 2: Advanced Data Engineering: We move beyond basic Spark, training your team on Delta Live Tables (DLT), sophisticated cluster optimization, and structured streaming for real-time analytics.
- Phase 3: MLOps & Deployment: We bridge the gap between data engineering and software engineering. Your team will master Databricks Asset Bundles, build multi-environment CI/CD pipelines, and integrate MLflow for model tracking.
Stop Hunting for Unicorns. Build Them.
True Databricks experts with deep architectural scars are exceptionally rare. Continuing to search for them while your platform accumulates technical debt is a losing strategy.
The highest-ROI move you can make is to empower the engineers you already trust. Equip your internal team with the architectural blueprints and hands-on guidance they need to unlock the platform’s full potential.