
Change Data Feed (CDF) in Delta Lake provides an efficient way to track row-level changes to a table over time.
In this article, I walk through how Change Data Feed (CDF) works in Delta Lake on Databricks, when to use it, how to query changes for incremental processing and auditing, and provide implementation examples with ready-to-use code.
What is Change Data Feed (CDF)?
Change Data Feed (CDF) is a native mechanism in Delta Lake that captures fine-grained changes—inserts, updates, and deletes—at the row level directly within your data tables. Unlike traditional methods that focus on the current state of the data, CDF preserves the full history of changes, recording what changed, how it changed, and when the change happened.
In contrast to traditional methods that scan entire tables or compare timestamps (which becomes extremely inefficient at scale), CDF allows systems to efficiently retrieve just the modified rows. For example, rather than comparing two multi-terabyte versions of a table, you can instantly access the handful of rows that were updated.
CDF empowers modern data architectures by enabling:
- Real-time analytics pipelines that respond immediately to data updates
- Efficient, incremental ETL workflows that process only new or changed records
- Machine learning systems that retrain models based on targeted data changes
- Audit and compliance solutions that require complete historical change tracking
How Traditional CDC Approaches Work
Traditional Change Data Capture (CDC) solutions—such as Debezium, Oracle GoldenGate, or AWS DMS—capture change events externally by reading database transaction logs. These events are then streamed into target systems for processing or replication.
While effective, traditional CDC comes with significant drawbacks:
- Architectural complexity: Requires external components like message brokers, staging areas, and coordination services
- Operational overhead: Adds maintenance, monitoring, and disaster recovery responsibilities
- Latency: Moving data across systems introduces delays, often unsuitable for real-time needs
- Cost: Enterprise CDC tools are expensive and resource-intensive
- Integration headaches: Stitching together different systems can lead to compatibility problems and technical debt
Traditional CDC solutions work outside the storage system and introduce multiple layers of complexity. As enterprises shift to cloud-native architectures, the demand grows for simpler, fully integrated approaches.
How Databricks Enables Change Data Feed (CDF)
Databricks takes a fundamentally different approach by embedding CDF directly into Delta Lake’s storage layer, removing the need for separate systems, log readers, or additional infrastructure.
How CDF Works in Delta Lake
Delta Lake uses a transaction log-based architecture where each table modification creates a new version. When CDF is enabled:
- Delta Lake records every row-level change (inserts, updates, deletes)
- Metadata captures the operation type, the table version when it happened, and both the old and new row values
- Partition information is stored to allow highly efficient access to changes
Because CDF is deeply integrated with Delta’s file and log format, it offers high scalability and low-latency change tracking—without needing any external CDC infrastructure.
Key Features of Databricks CDF
Databricks’ implementation of CDF comes with several advantages:
| Feature | Description |
|---|---|
| Native Integration | Built directly into Delta Lake; no external tools or extra infrastructure needed. |
| Fine-grained Control | Filter by operation type (insert/update/delete), time ranges, or table versions. |
| Scalability | Handles massive tables (billions of rows) with Delta Lake’s distributed architecture. |
| Versatility | Supports both batch and streaming pipelines for flexible processing needs. |
| Historical Replay | Enables „time travel” to view changes between any two table versions within the retention window. |
Enabling and Using CDF
Implementing CDF in Databricks is remarkably straightforward, requiring just a few simple commands.
Enabling CDF on a Delta Table
For a new table, you can enable CDF during table creation:
# SQL syntax
spark.sql(„””
CREATE TABLE customer_data (
id INT,
name STRING,
email STRING,
updated_at TIMESTAMP
)
USING DELTA
TBLPROPERTIES (delta.enableChangeDataFeed = true)
„””)
# Alternatively, using PySpark
from delta.tables import DeltaTable
DeltaTable.create(spark) \
.tableName(„customer_data”) \
.addColumn(„id”, „INT”) \
.addColumn(„name”, „STRING”) \
.addColumn(„email”, „STRING”) \
.addColumn(„updated_at”, „TIMESTAMP”) \
.property(„delta.enableChangeDataFeed”, „true”) \
.execute()
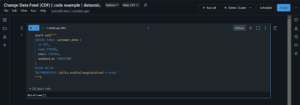
For existing tables, you can enable CDF with an ALTER TABLE command:
# SQL syntax
spark.sql(„ALTER TABLE customer_data SET TBLPROPERTIES (delta.enableChangeDataFeed = true)”)
# Using DeltaTable API
from delta.tables import DeltaTable
deltaTable = DeltaTable.forName(spark, „customer_data”)
deltaTable.properties().set(„delta.enableChangeDataFeed”, „true”)
Reading Change Data
Once CDF is enabled, you can access the change data using either SQL or DataFrame APIs:
Using SQL:
# Read changes between versions 5 and 10
spark.sql(„””
SELECT * FROM table_changes(’customer_data’, 5, 10)
„””).show()
# Alternatively, read changes starting from a specific timestamp
spark.sql(„””
SELECT * FROM table_changes(’customer_data’, '2023-01-01T00:00:00.000Z’)
„””).show()
Using DataFrame API:
# Read changes between versions
changes_df = spark.read.format(„delta”) \
.option(„readChangeData”, „true”) \
.option(„startingVersion”, 5) \
.option(„endingVersion”, 10) \
.table(„customer_data”)
# Or using timestamps
changes_df = spark.read.format(„delta”) \
.option(„readChangeData”, „true”) \
.option(„startingTimestamp”, „2023-01-01T00:00:00.000Z”) \
.table(„customer_data”)
Example Output
When reading change data, each record includes special metadata columns that indicate the type and context of the change:
| _change_type | id | name | updated_at | _commit_version | _commit_timestamp | |
|---|---|---|---|---|---|---|
| insert | 1 | John Smith | john.smith@example.com | 2023-01-01 10:00:00 | 5 | 2023-01-01 10:00:05.432 |
| update_preimage | 1 | John Smith | john.smith@example.com | 2023-01-01 10:00:00 | 7 | 2023-01-01 15:30:12.743 |
| update_postimage | 1 | John Smith | john.updated@example.com | 2023-01-01 15:30:00 | 7 | 2023-01-01 15:30:12.743 |
| delete | 2 | Jane Doe | jane.doe@example.com | 2023-01-02 09:15:00 | 9 | 2023-01-03 12:45:22.156 |
The special columns provide important context:
- _change_type: The operation type (insert, update_preimage, update_postimage, delete)
- _commit_version: The table version when the change occurred
- _commit_timestamp: The timestamp when the change was committed
Common Use Cases
Databricks’ implementation of CDF enables several powerful use cases:
Real-Time ETL Pipelines
CDF allows you to build efficient ETL pipelines that process only the changed data:
# Stream only changes since the last checkpoint
changes_df = spark.readStream.format(„delta”) \
.option(„readChangeData”, „true”) \
.table(„source_table”)
# Process changes and write to target
query = changes_df.writeStream \
.format(„delta”) \
.option(„checkpointLocation”, „/path/to/checkpoint”) \
.foreachBatch(process_changes) \
.start()
This approach dramatically reduces processing time and resource utilization compared to full table scans.
Machine Learning Feature Updates
For ML models that depend on frequently changing data, CDF provides an elegant way to update feature stores incrementally:
def update_feature_store(batch_df, batch_id):
# Process only new or modified features
inserts = batch_df.filter(„_change_type = 'insert’ OR _change_type = 'update_postimage'”)
# Update feature store with new values
inserts.drop(„_change_type”, „_commit_version”, „_commit_timestamp”) \
.write.mode(„append”).saveAsTable(„feature_store”)
# Handle deletes if needed
deletes = batch_df.filter(„_change_type = 'delete'”)
# Process deletes…
# Stream changes to feature store
spark.readStream.format(„delta”) \
.option(„readChangeData”, „true”) \
.table(„source_data”) \
.writeStream \
.foreachBatch(update_feature_store) \
.start()
Downstream Data Synchronization
CDF facilitates keeping systems in sync by propagating only the changes:
def sync_to_downstream(batch_df, batch_id):
# Prepare data for the destination system
batch_df.createOrReplaceTempView(„changes”)
# Format the data appropriately for the target system
processed_changes = spark.sql(„””
SELECT
id,
name,
email,
updated_at,
CASE _change_type
WHEN 'insert’ THEN 'I’
WHEN 'update_postimage’ THEN 'U’
WHEN 'delete’ THEN 'D’
ELSE NULL
END as operation_code
FROM changes
WHERE _change_type IN (’insert’, 'update_postimage’, 'delete’)
„””)
# Send to downstream system (e.g., using JDBC)
processed_changes.write \
.format(„jdbc”) \
.option(„url”, jdbc_url) \
.option(„dbtable”, „destination_table”) \
.mode(„append”) \
.save()
# Process changes in batch mode
changes_df = spark.read.format(„delta”) \
.option(„readChangeData”, „true”) \
.option(„startingVersion”, last_processed_version) \
.table(„source_table”)
sync_to_downstream(changes_df, 1)
Auditing, Compliance, and Historical Tracking
For regulated industries, CDF provides a ready-made audit trail of all data modifications:
# Create an audit log table
spark.sql(„””
CREATE TABLE audit_log (
table_name STRING,
operation_type STRING,
user_id STRING,
changed_at TIMESTAMP,
record_id INT,
old_value STRING,
new_value STRING
)
USING DELTA
„””)
# Function to record audit information
def record_audit_trail(batch_df, batch_id):
# Get current user
current_user = spark.sql(„SELECT current_user()”).collect()[0][0]
# Prepare audit records
batch_df.createOrReplaceTempView(„changes”)
audit_records = spark.sql(f”””
SELECT
'customer_data’ as table_name,
_change_type as operation_type,
’{current_user}’ as user_id,
_commit_timestamp as changed_at,
id as record_id,
CASE
WHEN _change_type = 'update_preimage’ THEN
to_json(struct(name, email, updated_at))
WHEN _change_type = 'delete’ THEN
to_json(struct(name, email, updated_at))
ELSE NULL
END as old_value,
CASE
WHEN _change_type = 'insert’ THEN
to_json(struct(name, email, updated_at))
WHEN _change_type = 'update_postimage’ THEN
to_json(struct(name, email, updated_at))
ELSE NULL
END as new_value
FROM changes
„””)
# Write to audit log
audit_records.write.mode(„append”).saveAsTable(„audit_log”)
Best Practices and Considerations
While CDF offers significant benefits, it’s important to use it judiciously and understand its limitations:
When to Enable CDF
CDF increases storage requirements since it preserves change information. Consider enabling CDF when:
- You need to track historical changes for compliance or auditing
- You have downstream systems that need incremental updates
- Your ETL processes would benefit significantly from processing only changed data
- You’re building real-time or near real-time data pipelines
For rarely changing tables or very large tables where storage costs are a concern, carefully evaluate the trade-offs.
Retention Settings
By default, change data is retained for 30 days. You can adjust this with table properties:
# Set retention to 7 days
spark.sql(„””
ALTER TABLE customer_data
SET TBLPROPERTIES (delta.logRetentionDuration = '7 days’)
„””)
Balance retention periods with storage costs and compliance requirements.
Performance Tuning Tips
To optimize CDF performance:
Use table partitioning effectively: Changes are tracked more efficiently when tables are properly partitioned.
# Creating a partitioned table with CDF enabledspark.sql(„””
CREATE TABLE events (
event_id STRING,
user_id STRING,
event_type STRING,
event_date DATE,
properties MAP<STRING, STRING>
)
USING DELTA
PARTITIONED BY (event_date)
TBLPROPERTIES (delta.enableChangeDataFeed = true)
„””)
Apply filters when reading change data: Limit the scope of changes to only what you need.
# Reading only specific partitions and operationschanges_df = spark.read.format(„delta”) \
.option(„readChangeData”, „true”) \
.option(„startingVersion”, 10) \
.table(„events”) \
.where(„event_date >= '2023-01-01′ AND _change_type IN (’insert’, 'update_postimage’)”)
Batch appropriately: For large change sets, process changes in reasonably sized batches.
Limitations to Be Aware Of
Understanding CDF’s limitations helps avoid surprises:
- Vacuum operations can remove change history if not configured properly. Always set retention periods longer than vacuum intervals.
- Schema evolution is supported, but major schema changes may complicate change tracking.
- Performance impact on write operations is generally minimal but depends on the size and frequency of changes.
- Storage costs increase with CDF enabled, especially for frequently updated tables.
Why CDF with Databricks is a Game Changer
Databricks’ implementation of Change Data Feed represents a significant advancement in how organizations manage and process changing data. By integrating change tracking directly into Delta Lake, Databricks has eliminated the need for complex external CDC systems while providing a scalable, performant solution for modern data engineering challenges.
The benefits are clear:
- Simplified architecture: No external systems, message queues, or additional infrastructure required
- Enhanced performance: Native integration with Delta Lake means minimal overhead
- Greater flexibility: Works seamlessly with both batch and streaming workloads
- Improved data reliability: Track exactly what changed and when with complete confidence
- Reduced costs: Process only what’s changed, dramatically reducing compute resources

By implementing CDF in your Databricks environment, you can transform how you handle changing data, moving from inefficient full-table processing to precise, incremental updates that save time, reduce costs, and unlock new use cases for your data.
To learn more about other powerful data management capabilities in Databricks, check out our articles on what is lakehouse architecture and how it differs from data lake and data warehouse, what is Unity Catalog and how it keeps your data secure, and what is Medallion Architecture in Databricks and how to implement it.
If you’re planning to implement CDF at scale, or need guidance on optimizing your Databricks environment for incremental processing, contact our experts — we’re ready to help you design efficient, future-proof data pipelines.