
Your data science team ships a model. Three weeks later, no one can reproduce it. The experiment tracking lives in a shared Confluence page, the feature pipeline was modified in-place, and the model artifact is a .pkl file on someone’s local drive. Meanwhile, the business is asking why the fraud detection accuracy dropped 4 points in production.
This is not a talent problem. It is an infrastructure and governance problem – and it compounds every sprint. Without a standardized MLOps layer, your ML organisation is running a distributed system with no contracts, no versioning, and no observability. The technical debt here is exponential, not linear.
At Dateonic, we implement MLflow on Databricks as a production-grade MLOps backbone – not as a demo environment, not as a proof-of-concept. We bring the architecture, the governance model, and the engineering rigour to organisations that are done tolerating ML chaos.
Why ML Pipelines Break at Scale
Most organisations reach the same failure point at roughly 15–30 models in production. Below that threshold, ad-hoc practices are painful but survivable. Beyond it, they become a business continuity risk.
The core dysfunctions are structural:
- No canonical experiment registry – teams run thousands of MLflow runs with no taxonomy, no tagging convention, and no owner. Finding the best run for a given dataset version requires a tribal knowledge transfer.
- Model lineage is severed – the connection between a registered model and its training data, feature engineering code, and hyperparameter sweep is implicit, not declarative.
- Promotion pipelines are manual – moving a model from Staging to Production in the Model Registry involves Slack messages, not automated quality gates.
- Inference infrastructure is inconsistent – some models serve via MLflow’s built-in REST endpoint, others via custom Flask wrappers, others via batch jobs. SLA management becomes impossible.
- Unity Catalog is not governing ML assets – model versions, feature tables, and training datasets live outside the governance perimeter, creating compliance exposure.
These are not edge cases. These are the default outcomes when MLflow is adopted organically rather than architecturally.
Advanced Technical Best Practices for Production MLflow on Databricks
1. Enforce a Hierarchical Experiment Taxonomy Backed by Unity Catalog
The MLflow experiment namespace should mirror your Unity Catalog three-level hierarchy: catalog.schema.experiment_name. This is not cosmetic – it enforces access control inheritance, makes cross-team discoverability deterministic, and ensures that model assets participate in Unity Catalog’s data lineage graph.
Concretely: register your models using the three-level namespace (catalog.schema.model_name) so that model versions are first-class Unity Catalog securable objects. This enables column-level lineage tracing from raw feature tables all the way to a deployed model endpoint, which is the audit trail your compliance team has been asking for.
import mlflow
mlflow.set_registry_uri(„databricks-uc”)
with mlflow.start_run(
experiment_id=mlflow.get_experiment_by_name(
„/Shared/fraud-detection/feature-eng-v3”
).experiment_id,
tags={
„team”: „risk-ml”,
„dataset_version”: „2024-Q4-v2”,
„feature_store_table”: „prod.risk.transaction_features”
}
):
mlflow.log_params(params)
mlflow.sklearn.log_model(
model,
artifact_path=„model”,
registered_model_name=„prod.risk.fraud_classifier”
)
2. Automate Model Promotion via CI/CD Quality Gates – Not Human Judgment
Model promotion from Challenger to Champion should be a deterministic, pipeline-driven event, not a Slack approval. Use Databricks Asset Bundles (DABs) to define your promotion logic as code, and trigger it from your CI system on merge to main.
A production-grade promotion gate should evaluate, at minimum:
| Quality Gate | Mechanism | Blocking? |
|---|---|---|
| Accuracy delta vs. Champion | MLflow MlflowClient.compare_runs() | Yes |
| Data drift on validation set | Evidently / custom metrics logged to MLflow | Yes |
| Inference latency (p99) | Load test via MLflow pyfunc | Yes |
| Schema compatibility | MLflow model signature enforcement | Yes |
| Fairness / bias check | Custom MLflow metric | Configurable |
The model alias system in MLflow 2.x (replacing the deprecated Staging/Production stages) gives you fine-grained alias semantics – @champion, @challenger, @shadow – that map cleanly to a multi-armed deployment strategy.
3. Standardize Feature Engineering with Databricks Feature Store and MLflow Autologging
The single most common cause of training-serving skew is feature computation logic that exists in two places: once in the training notebook and once in the serving pipeline. Databricks Feature Store eliminates this by making the feature table the contract between training and inference.
When you log a model trained on Feature Store data, MLflow automatically records the feature table lineage – which tables, which keys, which version of the lookup function. At serving time, the Feature Store SDK reconstructs the exact feature computation graph. Training-serving skew becomes architecturally impossible, not just unlikely.
Enable MLflow Autologging at the cluster level via mlflow.autolog() in your init scripts. For XGBoost, LightGBM, and scikit-learn, this gives you zero-code parameter, metric, and artifact tracking – but more importantly, it enforces tracking consistency across teams regardless of individual discipline.
4. Instrument Model Serving Endpoints for Operational Observability
Deploying a model to a Databricks Model Serving endpoint without observability is the equivalent of running a microservice with no APM. The endpoint payload logging feature – which routes inference requests and responses to a Delta table – should be mandatory, not optional.
From that Delta table, build a Model Monitoring job (using Databricks Lakehouse Monitoring or a custom implementation) that computes statistical drift metrics on a rolling window and logs them back to MLflow as time-series metrics. Alert thresholds should trigger automated Challenger training runs, not manual investigation tickets.
Key metrics to monitor per endpoint:
- PSI (Population Stability Index) on input feature distributions
- Label drift (for models with delayed ground truth, use proxy metrics)
- Prediction distribution shift – a leading indicator before accuracy degrades
- Token-level latency for LLM-backed endpoints (p50, p95, p99)
💡 Ready to fix this? Stop tolerating ML chaos – Dateonic will implement a production-grade MLOps standard on your Databricks environment in a structured 8-week engagement. Schedule your MLOps Architecture Review with Dateonic →
The Dateonic MLOps Standardisation Methodology
We do not deliver slide decks. We deliver working architecture. Here is exactly how we engage:
Step 1: MLOps Maturity Audit (Week 1–2)
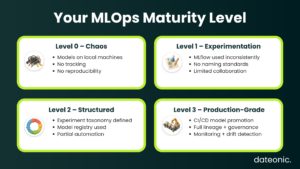
We instrument your existing MLflow environment and extract quantitative signals: experiment run volume, tagging coverage rate, model registration frequency, promotion lead time, and serving endpoint error rates. We map your current state against the MLOps Maturity Model (Level 0 → Level 3) and identify the two or three structural interventions with the highest leverage.
Deliverable: MLOps Maturity Report with prioritised remediation backlog.
Step 2: Architecture Blueprint & Governance Design (Week 2–3)
We design the target-state architecture: Unity Catalog namespace taxonomy, MLflow experiment hierarchy, Feature Store integration points, Model Registry promotion workflow, and serving endpoint topology. We document access control policies, tagging standards, and model card requirements as Databricks Asset Bundle configurations – infrastructure as code from day one.
Deliverable: Architecture Decision Records (ADRs) + DAB templates committed to your repository.
Step 3: Reference Implementation (Week 3–6)
We build the reference pipeline end-to-end on one production use case from your backlog. This is not a toy example – it uses your data, your models, and your SLAs. The implementation covers: Feature Store integration, experiment tracking with Unity Catalog lineage, automated promotion gates in CI/CD, and Model Serving endpoint with payload logging and drift monitoring.
Deliverable: Production-deployed reference pipeline + internal enablement session for your ML engineers.
Step 4: Team Enablement & Handover (Week 6–8)
We run a structured enablement programme for your data science and ML engineering teams – not generic Databricks training, but pattern-based workshops using the reference implementation we built in Step 3. We establish a MLOps Guild structure with clear ownership, review cadences, and escalation paths.
Deliverable: MLOps Playbook (your internal standard), team certifications, and 30-day hypercare support.
Case Study: Prometheus – Fintech ML Platform at 14PB Scale
Prometheus, a global fintech democratising financial services for underserved communities, came to Dateonic with a structural ML crisis.
Their data science teams were operating across fragmented systems managing over 10 petabytes of data scattered across business units – fraud detection models, credit risk pipelines, and identity resolution workloads with no unified governance layer and no shared experiment infrastructure.
Cross-team data transfers took days, and graph-based fraud analytics that required near-real-time throughput were completing in hours to days – making responsive transaction monitoring operationally impossible.
Dateonic implemented the Databricks Data Intelligence Platform as the unified MLOps and data backbone. Unity Catalog became the single governance perimeter for all ML assets across data scientists, engineers, and analysts. Fraud detection and risk assessment pipelines were rebuilt on the Lakehouse, with MLflow providing the experiment lineage and model registry layer across all product lines.
The outcomes were material and measurable:
- 5x reduction in compute costs while processing twice the prior data volume
- 90% faster time-to-insight on fraud detection and risk assessment workflows
- Graph-based analytics that previously took days now complete in minutes, enabling real-time transaction monitoring
- 14PB of governed data accessible through Unity Catalog’s role-based permission model
- 3x increase in cross-team collaboration, directly accelerating new financial product development
The full case study is available at dateonic.com →
The Business Case for Standardising MLOps Now
Every week your ML organisation operates without standardised MLOps, you are accumulating compounding technical debt – in the form of model failures that take days to diagnose, compliance exposure from ungoverned model assets, and engineering time burned on manual promotion workflows instead of model development.
The ROI of a structured MLOps implementation is not theoretical:
- Faster time-to-production – from weeks to days, directly accelerating business value delivery
- Reduced incident response cost – models with full lineage and monitoring are diagnosed in minutes, not days
- Compliance readiness – Unity Catalog governance covers your model assets inside your existing data governance perimeter
- Team scalability – standards and automation mean your 10th data scientist is as productive as your first, without a proportional increase in coordination overhead
This is a solvable engineering problem. It requires the right architecture, the right tooling configuration, and an experienced implementation partner who has done it before.
Contact our Databricks Experts to Implement MLOps Standards in Your Organisation →