
Most organizations attempting to deploy AI on internal data follow the same initial path: a Python script, a PDF loader, a vector store, and an API call to a public LLM endpoint. It works in a demo. In a regulated production environment – where a clinical trial document, an M&A brief, or a client financial record is the input – that architecture is simply not viable.
The problem is not the LLM itself; the problem is the complete absence of a data governance layer between the document corpus and the model inference endpoint.
The architectural gap is predictable. Frameworks like LangChain and LlamaIndex are orchestration libraries, not security platforms. They do not enforce column-level access controls, they do not integrate with enterprise identity providers at the vector retrieval layer, and they do not provide audit trails that satisfy SOC 2, HIPAA, or the newly enforced EU AI Act compliance requirements.
This article details what a production-grade architecture for running AI on internal data actually requires – and how the Databricks Data Intelligence Platform resolves these requirements natively, focusing on secure governance and high-quality data pipelines.
The Architectural Problem: Why Naive RAG Fails in Enterprise Environments
The canonical proof-of-concept Retrieval-Augmented Generation (RAG) pipeline introduces distinct security and quality surfaces at every component: ingestion, chunking, embedding, vector storage, and inference.
In regulated industries, routing an inference call to a third-party API endpoint – transmitting retrieved excerpts from sensitive documents outside the organizational perimeter – is a hard blocker. The architecture must be redesigned from the governance layer up, not patched at the application layer.
| Component | Naive RAG (POC) | Enterprise RAG (Production) |
|---|---|---|
| Data Security | No isolation, external APIs | Runs fully inside VPC/VNET |
| Access Control | Index-level only | Row & document-level (identity-aware) |
| Data Lineage | Not available | Full traceability (end-to-end) |
| Compliance | Not compliant | SOC 2, HIPAA, EU AI Act ready |
| Chunking Strategy | Fixed-size chunks | Semantic / context-aware chunking |
| Data Quality | Minimal preprocessing | Deduplication, enrichment, filtering |
| Vector Search | Basic similarity search | Hybrid (semantic + keyword) |
| Inference Layer | External LLM APIs | Controlled / self-hosted endpoints |
| Audit Logging | None | Full input/output logging |
The Three Security Failure Modes
- Flat Vector Store Access Control: Most standalone vector databases operate on index-level ACLs. A user with read access to the index retrieves chunks from any document ingested into that index. There is no row-level or document-level filter tied to the organizational identity hierarchy (IdP).
- No Lineage from Raw Document to Retrieved Chunk: When a retrieved chunk surfaces a factual error or a compliance violation, the organization must be able to trace that chunk back to its source document and the ingestion pipeline that processed it. Without integrated data lineage, this audit trail does not exist.
- Perimeter Leakage at Inference Time: Every call to external APIs (like GPT-4.5, Claude 3.5, or Gemini) transmits the full prompt payload to infrastructure outside the enterprise’s control, violating the principle of data minimization and standard NDA obligations.
The Databricks-Native Architecture for Secure AI
Databricks addresses these failure modes through integrated platform capabilities. The key architectural insight is that the entire RAG pipeline can be executed within a single Databricks workspace, backed by a customer-managed cloud account (AWS, Azure, or GCP), with no data ever leaving the organizational VPC/VNET.
Unity Catalog as the Governance Layer
Unity Catalog is Databricks’ unified governance solution. In a secure RAG pipeline, its role extends far beyond traditional catalog functionality:
- Table and Volume ACLs: PDFs ingested into a Unity Catalog Volume inherit the same identity-aware access controls as structured Delta tables.
- Column Masking & Row Filters: Allow selective exposure of document-level metadata without exposing the sensitive document body.
- Automatic Lineage Tracking: Every transformation – from raw PDF to parsed text to embedding chunk – is captured as a lineage edge, fully queryable via the Catalog API.
High-Quality Unstructured Data Pipelines
A secure architecture is useless if the retrieval quality is poor. Building an unstructured data pipeline requires meticulous preprocessing before data ever hits the vector index:
- Advanced Parsing & Enrichment: Raw text must be cleaned and enriched. Extracting contextual metadata (document level, structural headers, domain-specific tags) is vital. This metadata is later used to power highly secure, identity-aware filtering during retrieval.
- Deduplication & Filtering: Duplicate documents dilute the vector space. Implementing techniques like MinHash for deduplication ensures the LLM receives diverse context. Furthermore, toxicity and PII filtering classifiers must be applied at the pipeline stage to prevent sensitive data from even entering the vector index.
- Strategic Chunking: Moving beyond naive fixed-size chunking (which breaks semantic coherence), production systems utilize paragraph-based or semantic chunking to ensure the embedded vectors represent complete, meaningful thoughts.
Vector Search with Document-Level Access Isolation
Databricks Vector Search is backed by a Delta table in Unity Catalog, inheriting its ACL semantics. The implementation pattern guarantees security:
The Retrieval Guardrail: During ingestion, chunk records are annotated with allowed_groups metadata. At query time, the Mosaic AI Vector Search client applies a metadata filter that intersects the query with the caller’s SCIM-synced group membership (e.g., Entra ID, Okta). Chunks the caller is not authorized to see are excluded before the context window is assembled.
Mosaic AI Model Serving and the AI Gateway
The inference layer enforces the perimeter boundary at the network level. Mosaic AI Model Serving deploys open-weight models (Llama 4.x, Mixtral, DBRX 2) as REST APIs entirely within the customer’s cloud account.
To manage these endpoints securely, the Databricks AI Gateway sits in front of the models and provides:
- PII Detection Guardrails: Redacting sensitive entities before the prompt reaches the model.
- Rate Limiting: Scoped per service principal to prevent infrastructure abuse.
- Comprehensive Audit Trails: Input/output logging directly to a Delta table for SOC 2 compliance review.
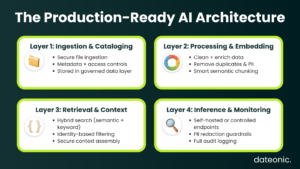
Implementation Blueprint: The Four-Layer Stack
A production-ready architecture for running AI on internal data securely consists of four discrete, tightly governed layers.
Layer 1: Ingestion and Cataloging
- Ingestion: Raw files are ingested via Databricks Autoloader or Lakeflow from enterprise content stores.
- Storage: Stored in Unity Catalog External Volumes, backed by cloud storage with customer-managed encryption keys (CMK/BYOK).
- Security: Document metadata is written to a Delta table with row-level security filters bound to SCIM group membership.
Layer 2: Preprocessing, Chunking, and Embedding
- Pipeline Logic: Executed as a Databricks Workflow, incorporating deduplication (MinHash) and PII filtering.
- Chunking: Semantic or format-specific chunking strategies are applied to maintain document context.
- Embedding: Domain-specific or general-purpose models (e.g., BGE-M4) are deployed on the cluster. No embedding API calls leave the workspace.
- Indexing: Chunk records are written to the Vector Search backing Delta table with their corresponding ACL metadata.
Layer 3: Retrieval and Context Assembly
- Hybrid Search: Query-time retrieval via the Databricks Vector Search SDK utilizes hybrid search (dense embeddings + sparse BM25 keyword search) for maximum recall on technical documents.
- Identity Filtering: Identity-aware metadata filtering is applied natively at the SDK level.
- Agent Orchestration: Context assembly is handled by Mosaic AI Agents, which provide built-in execution tracing via MLflow.
Layer 4: Inference, Evaluation, and LLMOps
- Inference: LLM generation via self-hosted Mosaic AI Model Serving or AI Gateway-proxied external endpoints.
- Evaluation & Monitoring: Utilizing MLflow Agent Evaluation to continuously assess RAG application quality, cost, and latency.
- Access: Application-layer access via a REST API endpoint secured with Databricks personal access tokens or OAuth M2M credentials.
Frequently Asked Questions (FAQ)
Can a Databricks RAG pipeline keep all document data within our cloud VPC?
Yes, and this is a core design goal of the Databricks Data Intelligence Platform. When deployed on a customer-managed cloud account (AWS, Azure, or GCP), all compute resources – including ingestion clusters, embedding endpoints, and LLM serving endpoints – run strictly within your VPC or VNET.
With Private Link enabled, a RAG pipeline can be configured with zero external data egress, easily satisfying data residency requirements for the EU AI Act and HIPAA.
How does Unity Catalog enforce access control on vector search results?
Unity Catalog enforces access control natively through the backing Delta table’s Row-Level Security (RLS) policies. Any ROW FILTER defined on the table is evaluated at query time against the caller’s service principal identity.
A legal associate querying the vector index for M&A documents will only retrieve chunks from deal rooms their specific identity group has access to. This filter acts at the storage layer and cannot be bypassed by application-level code.
How do you prevent PII leakage when using LLMs on internal data?
Production-grade systems handle PII at two layers. First, during the unstructured data pipeline phase, PII classification models identify and filter out highly sensitive documents before they are embedded.
Second, at inference time, the Databricks AI Gateway actively monitors inbound prompts and outbound responses, utilizing configurable AI guardrails to detect and redact any remaining PII before data is sent to the LLM.
What is the operational difference between Databricks AI Gateway and a self-hosted proxy like LiteLLM?
While self-hosted proxies like LiteLLM provide basic routing and logging, they require the customer to operate the infrastructure, build custom audit pipelines, and manually integrate enterprise IdPs. Mosaic AI Gateway is a fully managed, Databricks-native service integrated instantly with Unity Catalog lineage and MLflow.
It natively supports per-endpoint rate limiting for specific service principals, real-time PII scanning, and automatic SOC 2-compliant audit logging right out of the box.
Conclusion: A Governance-First Architecture
Running AI on internal data securely is an architectural problem, not a configuration problem. The answer is not a verify_ssl=True flag; it is a layered system where data governance, identity, pipeline quality, network perimeter, and compute isolation are co-designed from the beginning.
The Databricks Data Intelligence platform provides this entire stack as managed, integrated services. The architectural shift is from „an LLM wrapper with a vector database attached” to a „governed data product with AI inference capabilities.” That distinction is what separates a production-ready system from a proof of concept.
Ready to productionize your AI architecture? Contact Dateonic’s Engineering Team – we design and implement production-grade Enterprise RAG systems on Databricks for clients in Pharma, Finance, and Enterprise IT.