
In recent years, enterprise AI adoption faced a fundamental bottleneck: business units demanded frontier-model productivity, while security, compliance, and data governance teams strictly blocked external API access to third-party infrastructure. In 2026, this is no longer viewed as a cultural conflict – it is recognized as a strict data residency and threat-modeling baseline.
When a prompt is submitted to a public LLM or a naive API integration, the payload – often containing proprietary trade data, customer PII, or pasted internal documents – traverses external inference infrastructure.
Even under standard enterprise terms where data is not used for model training, processing occurs on third-party compute. For organizations governed by GDPR, HIPAA, the EU AI Act, or strict internal data classification frameworks, this remains a material compliance breach.
The legacy workaround of wrapping an external API in an orchestration pipeline and labeling it „private” is fundamentally flawed; data still leaves the corporate perimeter at inference time. The architectural standard has now shifted toward internal Retrieval-Augmented Generation (RAG) and agentic frameworks, where the LLM runs on private compute or via a governed API gateway with contractual zero-retention guarantees.
Infrastructure Realities: Data Exposure Vectors
Evaluating AI security requires understanding exactly what happens at the infrastructure level. Every external API call introduces three distinct data exposure vectors:
- Prompt Payload: The user query, heavily augmented by retrieved context chunks (text, images, structured data) injected directly into the context window.
- System Prompt Leakage: The proprietary retrieval logic, agentic routing instructions, and business rules configured by the engineering team, which are transmitted with every call.
- Retrieval Artifacts: Naive pipelines often inject the full text of retrieved document chunks verbatim, meaning entire paragraphs of sensitive internal documentation leave the perimeter continuously.
A production-grade internal RAG architecture neutralizes these vectors by isolating inference entirely within the enterprise trust boundary.
Platform-Native Architectures for Unified Governance
To eliminate the fragmentation and technical debt associated with bespoke AI deployments, organizations are standardizing on platform-native architectures. Ecosystems that unify data engineering and AI inference – such as Databricks – serve as excellent reference models for this approach.
A robust internal architecture relies on several foundational pillars:
- Unified Governance (Unity Catalog): Modern architectures manage access across all assets – unstructured files in Volumes, vector indexes, model artifacts, and structured tables – under one control plane. Row-level and column-level security apply directly at the data plane. A query from a user only surfaces document chunks their ACL permits, ensuring compliance by default.
- Managed, In-Perimeter Vector Search: Rather than maintaining standalone databases, modern vector indexes (like Mosaic AI Vector Search) are treated as managed derivatives of underlying Delta tables. This ensures automated, incremental synchronization when source documents update, sharing the same secure compute environment.
- Centralized AI Gateways: A managed gateway acts as a proxy for all LLM traffic. It provides pre-processing guardrails (PII detection), comprehensive audit logging to Delta tables, and dynamic routing between internal open-weights models and secure external endpoints.
The Data Pipeline: The True Differentiator for RAG Quality
The most common reason internal RAG initiatives fail to match ChatGPT’s perceived quality is not a lack of LLM intelligence, but a failure in the unstructured data pipeline. As highlighted in modern enterprise AI playbooks, the performance of a RAG system is strictly bound to data preparation.
A production-grade pipeline requires deep integration with data engineering tools to handle:
- Complex Document Parsing: Enterprise data lives in messy PDFs, slide decks, and scanned documents. The pipeline must intelligently extract text while preserving the layout, reading embedded tables correctly, and interpreting image content.
- Semantic Chunking Strategies: Splitting documents by arbitrary character counts destroys context. Advanced pipelines use semantic chunking – breaking documents by logical sections, paragraphs, or document structures – so the LLM receives cohesive thoughts.
- Metadata Enrichment: Extracted chunks must be tagged with robust metadata (e.g., document source, date, author, department, and summary tags). This allows the vector search to perform pre-filtering before the semantic search even begins, drastically reducing hallucinations.
By leveraging platforms that native integrate data engineering (e.g., Delta Live Tables) with AI workflows, organizations can build robust pipelines that ensure high-quality, cleansed data feeds the vector index.
Performance, Latency, and Retrieval Trade-offs
The historical assumption that internal RAG underperforms external frontier models is obsolete in 2026. The capability gap for specialized enterprise tasks has closed.
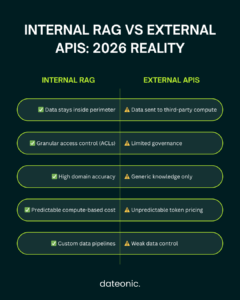
| Architectural Dimension | Internal RAG Architecture | External Enterprise APIs |
|---|---|---|
| Data Residency | Strictly within perimeter | Third-party compute |
| Access Control | Granular data-plane ACLs | Application-level or siloed |
| Data Pipeline Quality | High (Custom chunking & parsing) | Low (Blind file uploads) |
| Domain Accuracy | High (Deeply grounded in context) | Low (Lacks internal knowledge) |
| Cost Predictability | High (Compute-based) | Low (Unbounded token pricing) |
Models like Llama 4 70B or Mistral Large 3, deployed on managed infrastructure, routinely match or exceed the performance of broad frontier models on domain-specific extraction. A heavily optimized retrieval pipeline feeding a mid-tier internal model yields far more accurate, verifiable results than relying on the parametric memory of a public model.
MLflow and Observability as a First-Class Concern
Production RAG requires continuous monitoring. Retrieval quality degrades as corporate knowledge bases evolve, and model updates introduce regression risks.
Engineering teams must implement robust observability – leveraging standards like MLflow Evaluate – to systematically measure retrieval precision, answer faithfulness, and relevance using built-in metrics. Furthermore, agentic tracing allows teams to log every retrieval step, chunk score, and latency metric. Without this telemetry, an AI system is an unmeasurable black box; with it, it becomes a predictable, SLA-compliant software component.
Common Architectural Questions
Is it possible to use external frontier models without sending proprietary data to their public infrastructure?
Yes, but with caveats. Azure OpenAI Service with VNET integration and a zero-retention API agreement remains the standard enterprise workaround. Prompts are not used for training and do not traverse public endpoints. However, data still leaves your perimeter to Microsoft Azure compute.
For strict on-premises, sovereign cloud, or highly regulated requirements, self-hosted open-weights models (e.g., Llama 4) on Databricks Model Serving with no egress is the only architecture with a true zero-residency guarantee.
How does Unity Catalog handle vector search access controls for RAG?
Unity Catalog applies the same granular ACL framework to Mosaic AI Vector Search indexes as it does to standard Delta tables. Row-level and column-level security policies enforce which document chunks a specific user principal can retrieve during a RAG query.
This is enforced directly at the data plane level, completely eliminating the risk of application-layer bypass. In practice, this means a marketing manager querying an internal knowledge base will never receive retrieved chunks from HR or M&A documents they are not authorized to access – all without requiring any custom filtering logic in the orchestration layer.
What is the production readiness difference between a LangChain wrapper and a Databricks-native RAG architecture?
A framework wrapper (like LangChain or LlamaIndex) handles orchestration logic but externalizes every production concern – access control, audit logging, model versioning, retrieval freshness, cost governance, and evaluation – to the application developer.
A Databricks-native architecture addresses each of these concerns systematically through managed platform components: Unity Catalog (governance), AI Gateway (audit + cost routing), Mosaic AI Vector Search (retrieval freshness), Model Serving (compute scaling), and MLflow (evaluation + tracing). The technical debt and maintenance liability required to build and secure a bespoke wrapper architecture are fundamentally eliminated.
Conclusion
The architectural decision between internal RAG and public APIs is no longer a debate about model capabilities – it is a strategic mandate on data architecture, pipeline quality, and operational ownership. While external APIs offer rapid prototyping, they expose regulated enterprises to unacceptable compliance risks and fail to deliver the granular data control required for true business value.
By adopting a unified, platform-native architecture on Databricks, organizations can keep inference strictly within their perimeter, enforce unified access controls, and guarantee high-quality context ingestion. However, transitioning from a proof-of-concept to a production-grade, compliant AI system is a complex engineering challenge that spans advanced data engineering, MLflow observability, and secure MLOps.
This is where Dateonic bridges the gap.
Building enterprise-grade RAG should not mean months of trial and error or risking compliance breaches. As specialized experts in Databricks-native AI architectures, Dateonic’s Engineering Team designs, builds, and deploys secure, scalable internal RAG systems tailored for heavily regulated industries. We do not just provide advisory services; we deliver end-to-end technical implementation – from building custom document parsing pipelines and enforcing Unity Catalog governance to deploying state-of-the-art open-weights models on private compute.
Stop compromising between AI productivity and enterprise security. Contact Dateonic today to schedule an AI Architecture Review, and let our experts accelerate your deployment of a secure, production-ready generative AI ecosystem – fully within your data perimeter.